Using deep learning to classify objects
When a phone asks a neural network what it sees.
· 8 min read
Among the millions of images uploaded online every day, only a few are processed. Humans are not efficient enough to label such a large amount of data. As a group of 5 students, we decided to automate this process by extracting image information with machine learning.
We built SmartSight, a system that provides information about any image. It exposes an API that calls a classification engine, demonstrated through an Android application.
Check the organization on GitHub.
Conception
Global architecture
The basic idea of our solution is fairly simple:
- We send an image as input to our system
- Our system processes and classifies this image
- The system outputs a set of predicted classes

The SmartSight box, representing the engine, is a black box that only knows about the inputs it receives. It returns a batch of titles associated with scores. The titles represent the classes inferred by the engine, and the scores represent its confidence in each result.
Detailed architecture
From the start, we had a clear idea of how the different services would work together to form a complete system. However, we considered two different solutions:
- Embed the whole system into the mobile device
- Design a microservice system communicating with the mobile device
Solution (1) could be seen as the easiest to implement. We would only need to embed the machine learning engine into the mobile application, without any internet connection, leading to the theoretically fastest result. The downside is that the computing power of each mobile device varies a lot. The type of algorithm used for classification is computationally expensive and drains the battery. Another drawback is that all the data needed to classify the image would need to be stored on the device, which is not fair to the user.
We opted for solution (2), which is a modular architecture containing an API, an engine, and the mobile application.
There are two distinct parts: the training phase and the utilization phase. During the training phase, the engine tries to find the best parameters (the weights) using a training algorithm (Back Propagation). The utilization phase begins once the system has been trained.
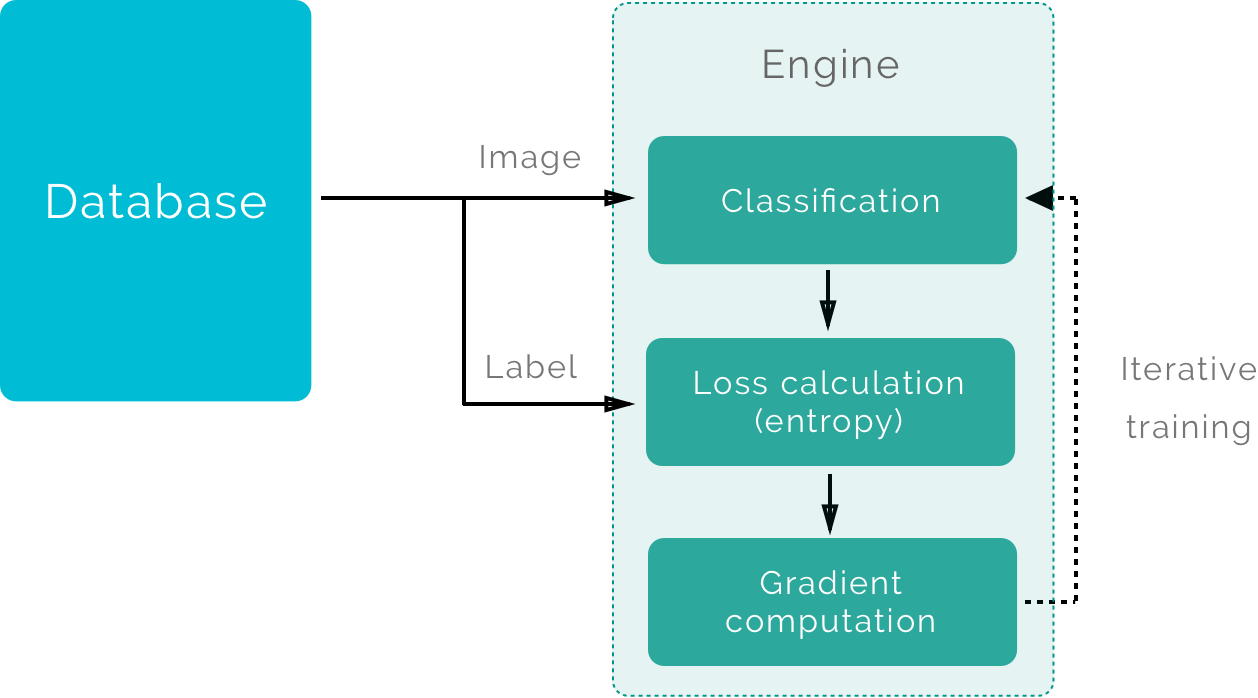
Once trained, the flow of this architecture is the following:
- The mobile device sends the image to the server’s API
- The server receives the image and runs the engine with the image as input
- The engine processes the image and sends the results back to the parent process
- The server sends the response back to the mobile device
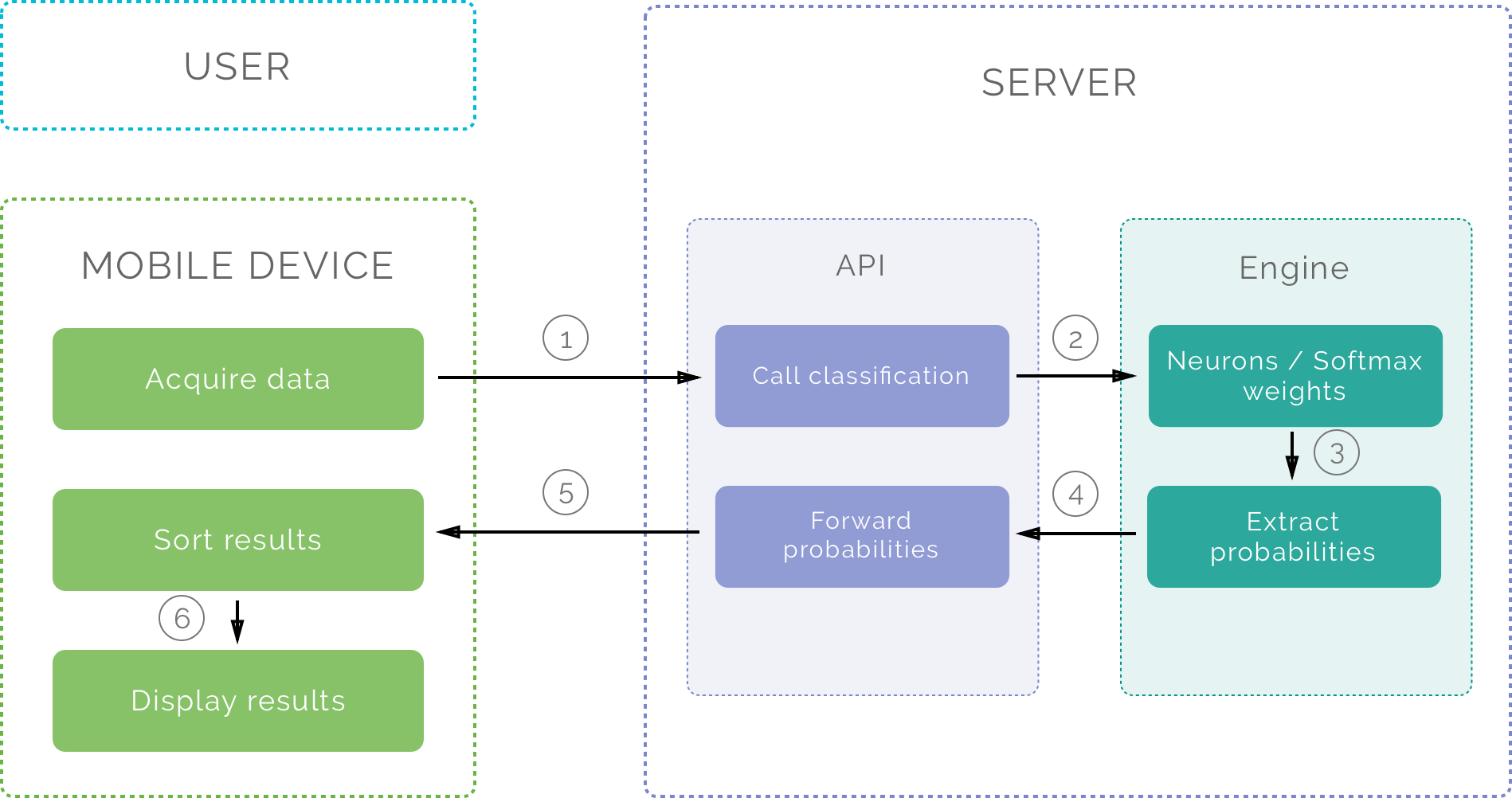
This solution takes advantage of the server's computing power to execute the classification script that we called the engine. The time lost sending the image from the device to the server is compensated by this more powerful engine. The downside is that it needs an internet connection to work.
Execution
The SmartSight project has been fully open source from the start. All the assets and code are available on the GitHub organization. This environment is highly efficient because it allows the team to create each module as a GitHub repository.
SmartSight API
![]()
The SmartSight API is the server of the system. It is the interface that links the Android application and the core engine. The server was hosted locally during development and on its own server in production.
This service is versioned and offers a single route, POST /v1/classify, that accepts an image as input and returns predictions about it (see full documentation). It is good practice to version an API to avoid introducing breaking changes: if we drastically change the output of the route, we would create a second version of our API so that client applications still using version 1 of the classify route continue to work.
{
"meta": {
"type": "success",
"code": 200
},
"data": [
{
"score": 0.884148,
"class": "pizza, pizza pie"
},
{
"score": 0.002444,
"class": "butcher shop, meat market"
},
{
"score": 0.00208,
"class": "carbonara"
},
{
"score": 0.002078,
"class": "trifle"
},
{
"score": 0.001326,
"class": "pomegranate"
}
]
}POST /v1/classifyThis API was developed using NodeJS, which is JavaScript on the server side. Koa is an abstraction of the NodeJS http module that made the API more enjoyable to write. This library uses JavaScript promises and asynchronous functions to avoid callbacks and make the code easier to reason about.
Since this API depends on the core Python engine, we need to reference the engine in the API. We used the very convenient Git Submodules to share a clean development environment.
SmartSight Android
![]()
The SmartSight Android application targets the Android API level 21, corresponding to devices running at least Android 5.0. It communicates with the SmartSight API by sending the image taken with the device’s camera and displays the results back on the screen.
The application was developed with Kotlin, a new statically-typed programming language by JetBrains running on the JVM. It compiles to JVM bytecode (Java and Android), and JavaScript. We chose Kotlin to avoid the verbosity of Java. It makes our code cleaner and easier to reason about, with null safety (no more NullPointerException), type inference, functional programming support, string interpolation, unchecked exceptions, extension functions, and operator overloading.
SmartSight engine
![]()
The SmartSight engine is the core of the system. It is an image recognition algorithm based on Tensorflow and trained on the ImageNet dataset. It outputs the results of the predictions as a JSON array of objects.
[
{
"class": "pizza, pizza pie",
"score": 0.884148
},
{
"class": "butcher shop, meat market",
"score": 0.002444
},
{
"class": "carbonara",
"score": 0.00208
},
{
"class": "trifle",
"score": 0.002078
},
{
"class": "pomegranate",
"score": 0.001326
}
]Each object in the JSON array contains two keys: class and score. The class refers to the object recognized by the algorithm as a string. The score is a confidence value for this prediction as a float.
SmartSight art
![]()
Eventually, we stored all assets for the project in a SmartSight Art repository. This repo is useful for tracking design changes over time, and especially for using consistent logos and assets across all SmartSight modules.
All the assets were designed as vectors, meaning they can be enlarged and zoomed as much as needed without pixelating.
Tests
Functional tests
Throughout the development of the SmartSight API, tests drove the development. We call this strategy Test Driven Development (TDD). Since the API was developed in NodeJS, we used the modern test library AVA to write our tests.
These tests made sure the API returned the correct status codes and data format.
test.cb(`POST ${endpoint} with JPG image returns 200`, (t) => {
api
.post(endpoint)
.attach('file', 'test/fixture/pizza.jpg')
.expect(200)
.end((err, res) => {
if (err) {
throw err;
}
t.end();
});
});Performance tests
The classification core performs more than 95% successful predictions on the ImageNet database. The system is not able to label an object it has not been trained on.
We conducted several tests, searching for an interesting image preprocessing phase that would improve the system's performance. The important features we took into account were luminosity, noise, blur, and compression. When we test on only one image, the result is inconclusive and doesn't really make sense. The score of an image varies a lot depending on its original settings. A low-luminance cat will score higher if the system has been trained on a low-luminance dataset.
Most of the time, we observed a score increase around 80% image compression. This could be explained by lower accuracy that ignores insignificant details. Moreover, this compression also speeds up the processing time.
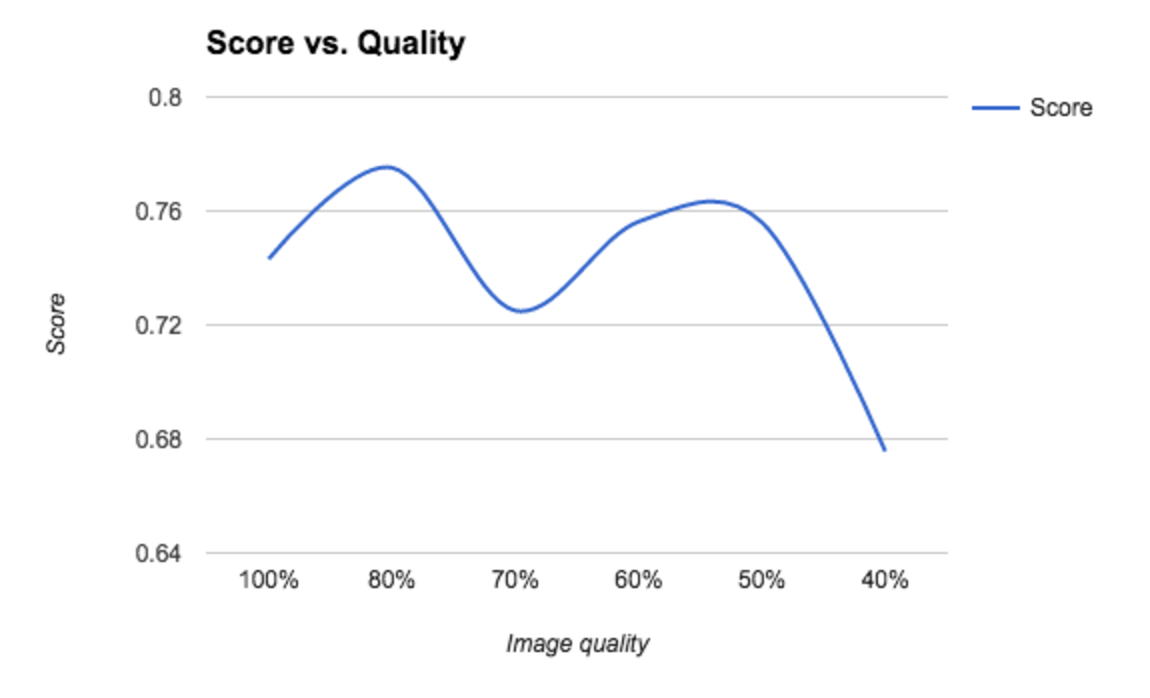
These tests are not relevant enough to conclude anything yet, as it would be more interesting to test across a large portion of the database.
Achievements
The most important aspect of our project was the development of a classification system. We created a simple, intuitive, and user-friendly Android application that uses the system by communicating with a server that runs the classification engine. Our reusable API is exposed and open source so that developers can contribute to the system.
Encountered problems
Our initial expectation was to create a user-focused application. The user would take a picture and, if it wasn't recognized, would upload the image to the system to add new classes to the classification system.
However, in order to add classes to the system, the entire classifier needs to be retrained from scratch. This process takes time and requires heavy computation.
We met Martin Görner, a machine learning expert, during a TensorFlow meetup in Paris. He advised us to have a look at transfer learning to bypass this issue.
After studying this approach, we found out that it doesn't actually solve our problem: transfer learning allows you to specialize the system for new precise classes by replacing the last layers of the neural network, but not to broaden the range of classes.
As of now, we are not able to improve the scope of objects without significantly lowering performance.